Accelerating Research with AI 生成式 AI 系統的工作原理
生成式 AI 的工作方式就像一個“文字填空遊戲”。當你給它一個句子時,它會根據之前的內容去預測下一個最有可能的單詞。它並不是一個“記憶力超強”的資料庫,而是一個“猜詞高手”。這種預測能力依賴於一種叫“神經網路”的技術,並且每個單詞在 AI 的眼中,都被看作是一個多維空間中的點(詞嵌入),這些點的相對位置決定了單詞之間的語義關係。
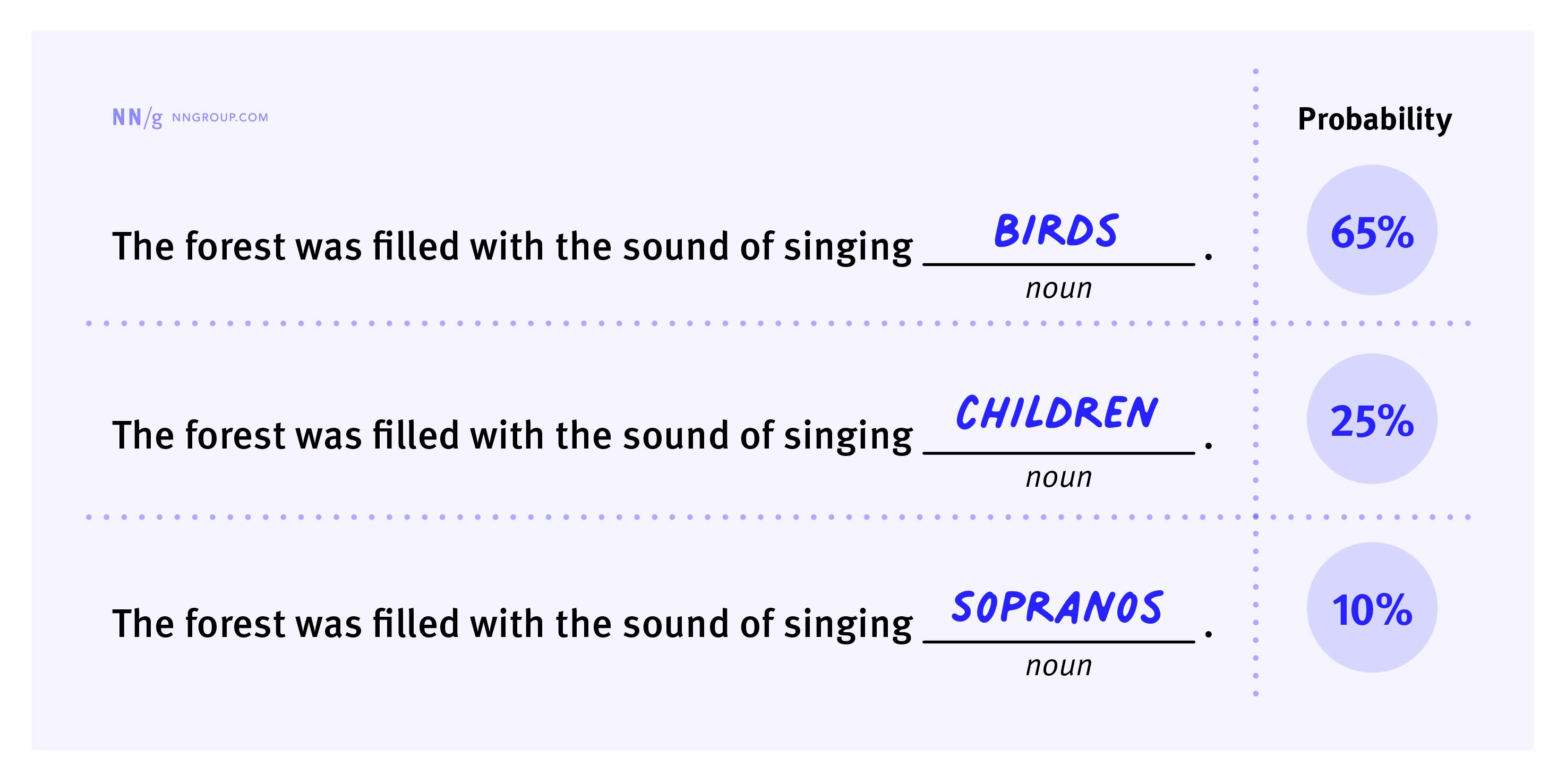
AI 預測單詞的方式:機率預測
生成式 AI 就像一個“填字遊戲玩家”。當你說:“它正在下著大雨貓和___”,AI 很有可能會接上“狗”,因為“貓和狗”是英文中一個常見的說法(It’s raining cats and dogs)。它的預測並不是隨機的,而是基於它在海量文字中學到的單片語合模式。

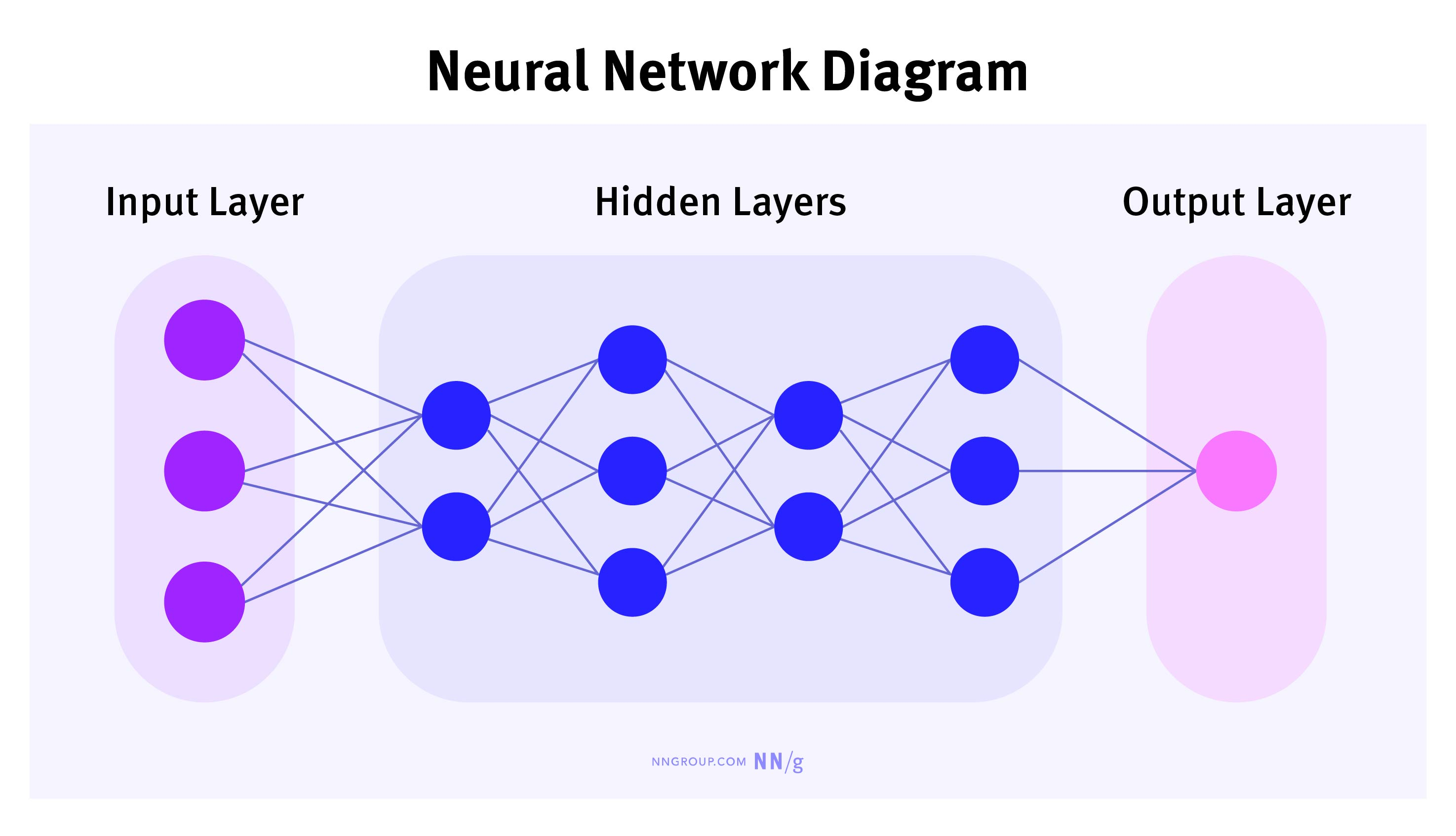
什麼是神經網路?
可以把神經網路想象成一組訓練有素的樂隊。每個神經元(樂手)自己演奏一個簡單的音符,但當多個神經元合作時,就能演奏出複雜的交響樂。神經網路由多個“層”組成:
- 輸入層:接收資訊(就像樂隊指揮的樂譜)。
- 隱藏層:進行資訊處理(每個樂手根據樂譜進行演奏)。
- 輸出層:生成結果(最終的樂曲)。
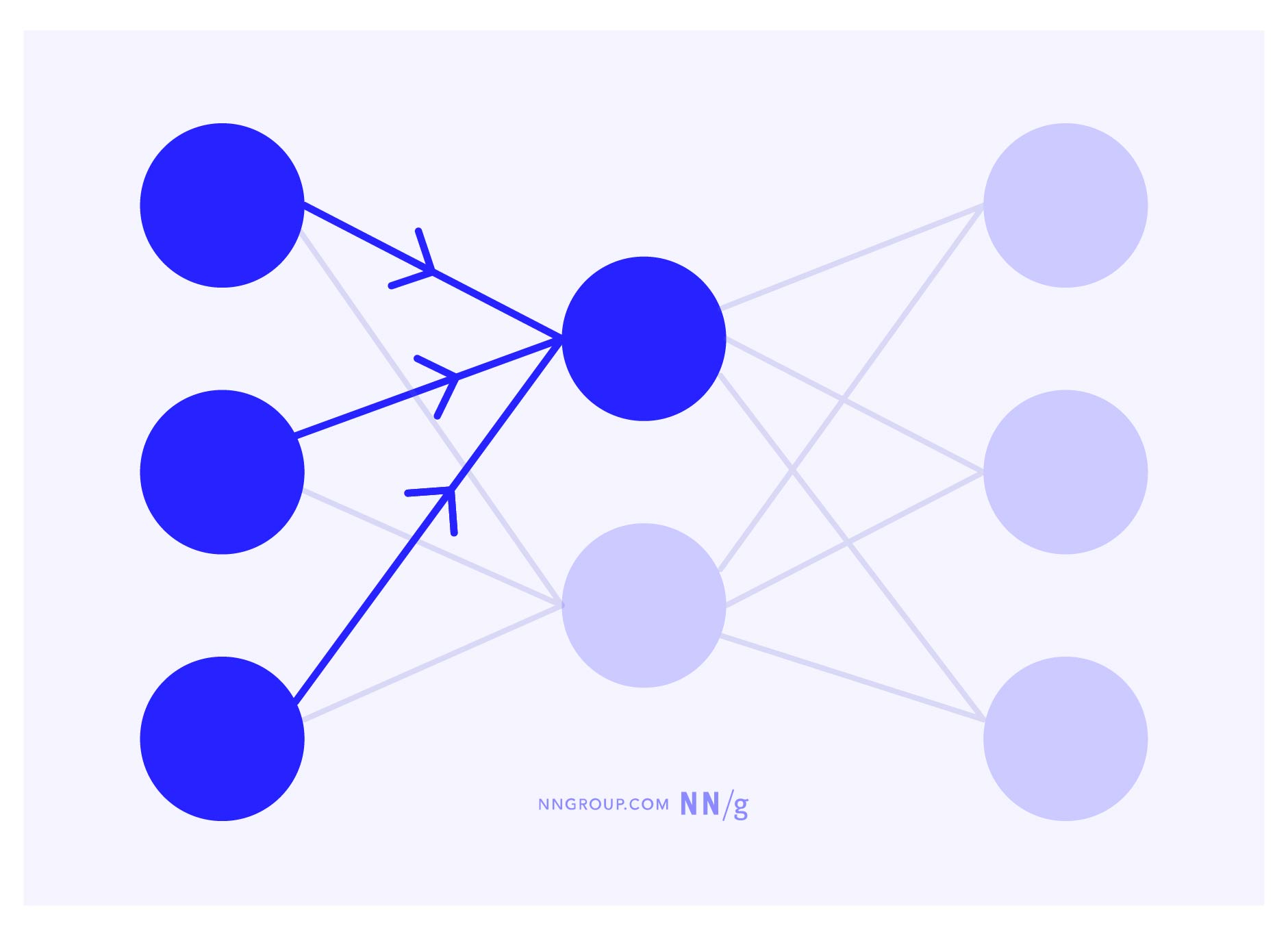
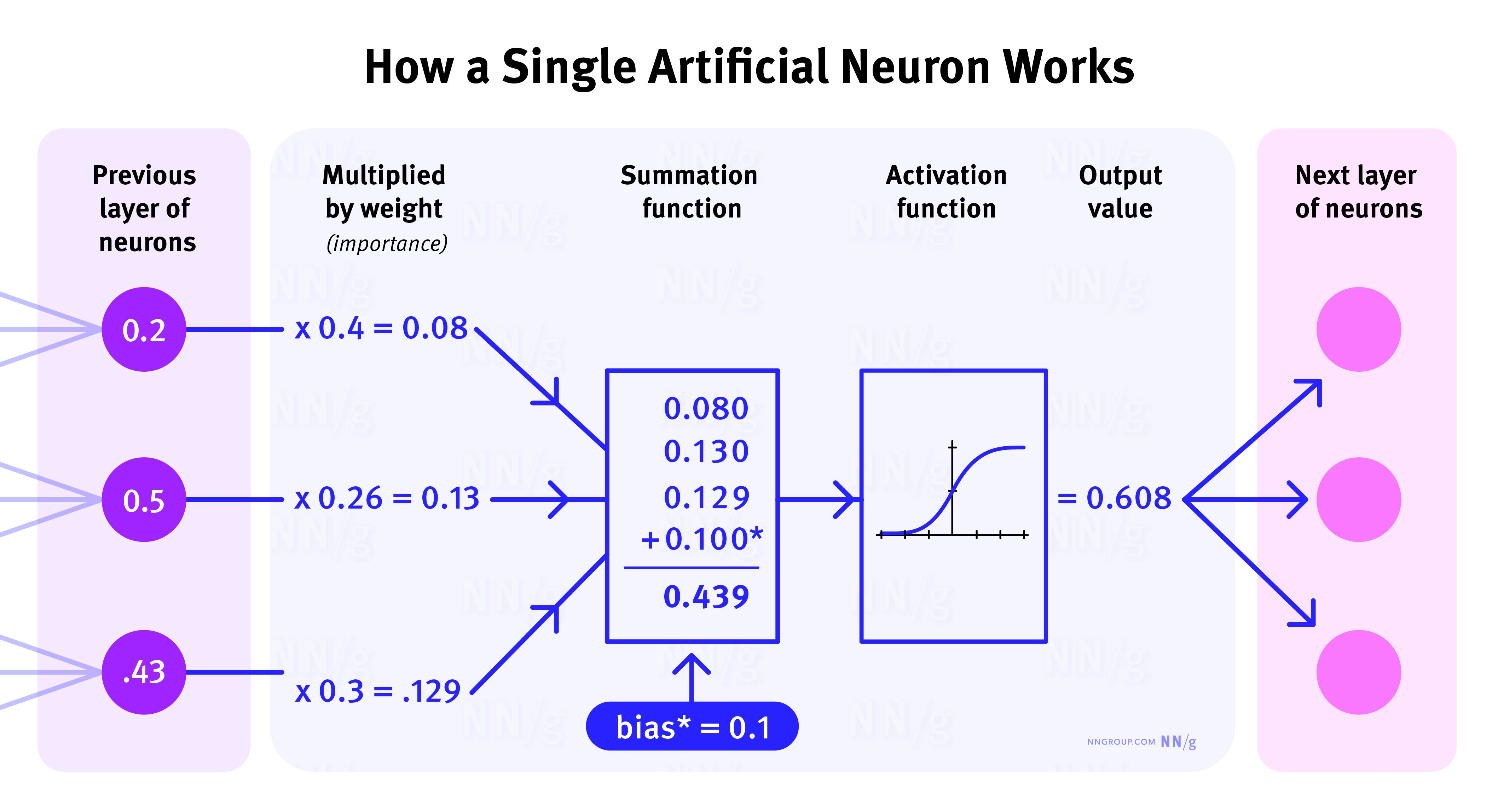
舉例來說,如果神經網路被輸入一隻貓的圖片,它可能先識別出“貓耳朵”、“貓眼睛”,然後綜合這些資訊,最終輸出“這是隻貓”的判斷。
單詞是如何被 AI 理解的:詞嵌入(Word Embeddings)
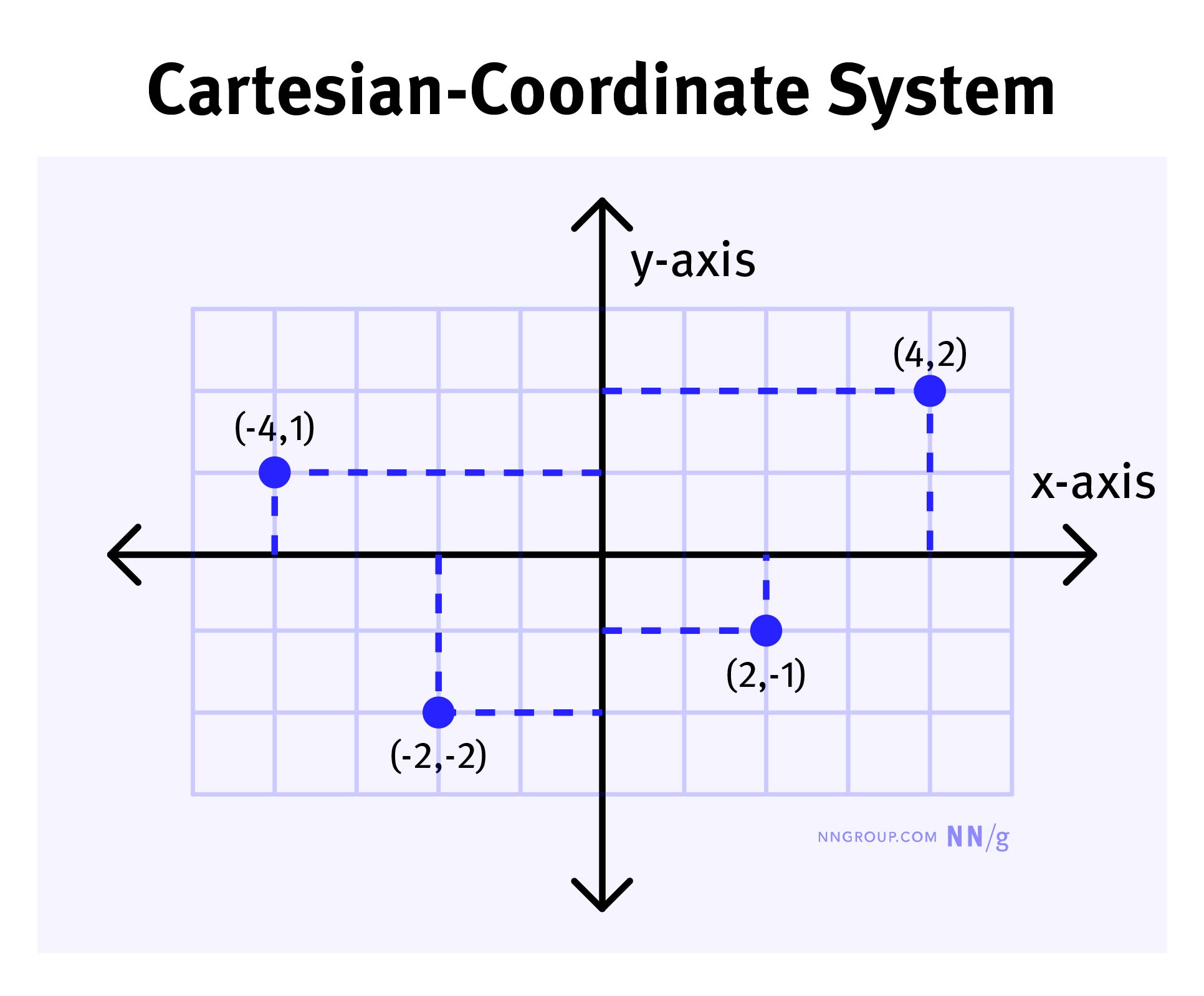
在 AI 的世界裡,單詞不是以文字形式存在的,而是被轉化成一種“座標”。想象一下,我們要在二維平面上定位一個點,我們會用 (x, y) 座標來表示它的位置。
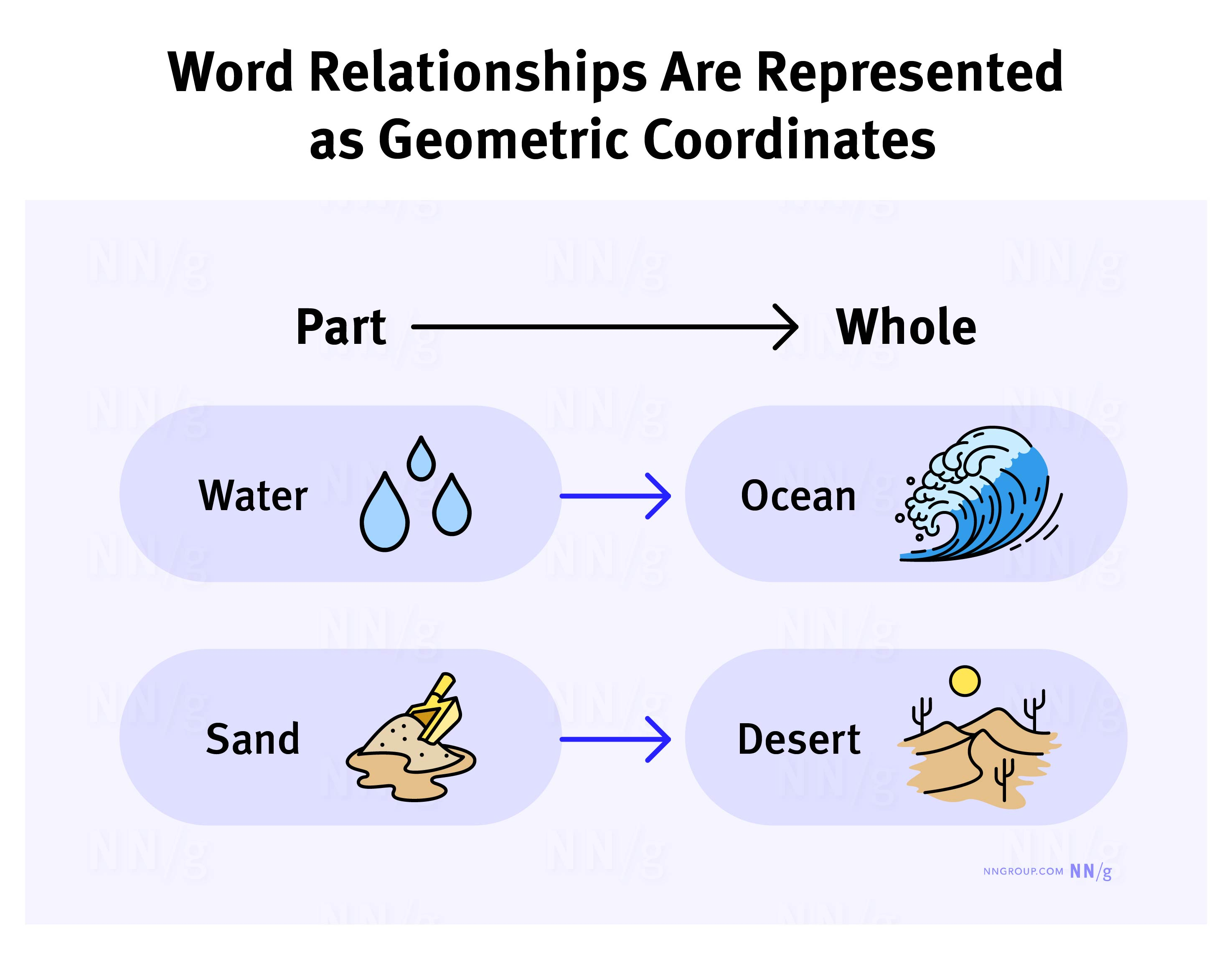
類似地,AI 會用一個多維的座標來表示單詞。例如,“水”這個詞會被放在接近“海洋”的位置,因為它們在語義上關係緊密。而“沙子”可能會被放在接近“沙漠”的位置。
透過這種方式,AI 可以透過“看”不同單詞之間的相對位置來推斷它們之間的關係。比如,“水”和“沙子”可能不會離得很近,但“水”和“冰”一定是在某個維度上非常接近的。
Transformer 架構:AI 的“超級大腦”
Transformer 是一種特殊的神經網路,它使得 AI 能夠高效地處理大量文字,並能理解上下文關係。
- 速度優勢:傳統的神經網路會一個字、一個字地處理資訊,而 Transformer 則可以同時處理多個單詞,大幅提升了訓練和運算速度。
- 上下文理解能力:Transformer 引入了一種叫“自注意力機制”(Self-Attention)的功能。它就像是每個單詞都“看著”整段文字中的其他單詞,並決定哪些單詞對它更重要。這樣,即使兩個相關的單詞隔著很多其他單詞,AI 仍然能保持它們的關聯,理解它們之間的關係。
AI 學習語言的過程
生成式 AI 透過"閱讀"海量網際網路文字來學習語言。它識別語法和語義規則,並不斷調整引數以生成符合人類邏輯的文字。經過多輪訓練和微調,AI 能夠生成自然的回覆。
- 生成式 AI 透過機率計算預測下一個可能的單詞。
- 它使用神經網路架構,將單詞表示為多維空間中的點。
- Transformer 模型提高了 AI 理解複雜上下文的能力。
這些原理使生成式 AI 能夠執行從簡單的單詞填充到複雜的文章生成和對話任務。